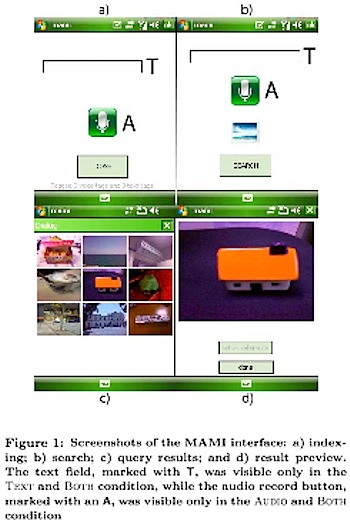
Two weeks ago I presented a paper at MobileHCI’09 titled: Text versus speech: a comparison of tagging input modalities for camera phones:
Speech and typed text are two common input modalities for mobile phones. However, little research has compared them in their ability to support annotation and retrieval of digital pictures on mobile devices. In this paper, we report the results of a month-long field study in which participants took pictures with their camera phones and had the choice of adding annotations using speech, typed text, or both. Subsequently, the same subjects participated in a controlled experiment where they were asked to retrieve images based on annotations as well as retrieve annotations based on images in order to study the ability of each modality to effectively support users’ recall of the previously captured pictures. Results demonstrate that each modality has advantages and shortcomings for the production of tags and retrieval of pictures. Several guidelines are suggested when designing tagging applications for portable devices.
[link to PDF] [DOI] [Slides of the presentation]
Full reference:
Cherubini, M., Anguera, X., Oliver, N., and de Oliveira, R. Text versus speech: a comparison of tagging input modalities for camera phones. In MobileHCI ’09: Proceedings of the 11th International Conference on Human-Computer Interaction with Mobile Devices and Services (New York, NY, USA, 2009), ACM, pp. 1–10.