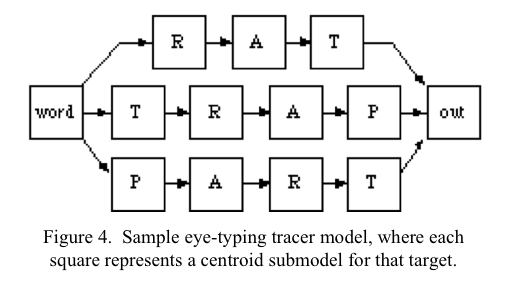
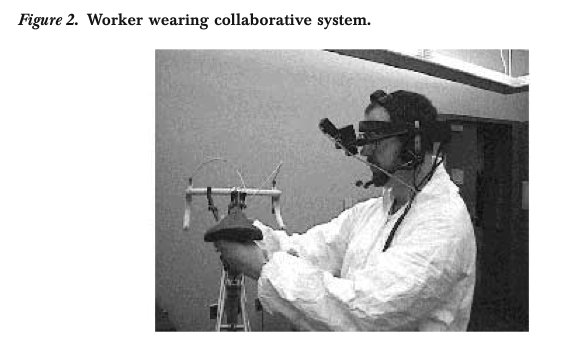
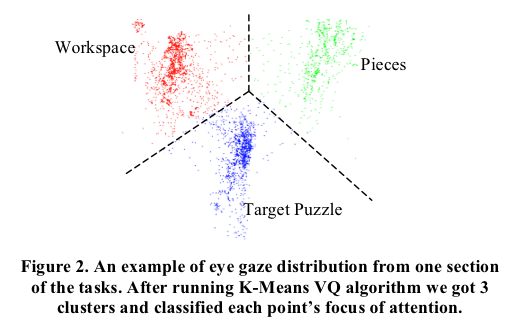
A. Meier, H. Spada, and N. Rummel. A rating scheme for assessing collaboration quality of computer-supported collaboration processes. International Journal of Computer Supported Collaborative Learning, 2(1):63–86, March 2007. [pdf]
———–
This paper defines a nine-dimension rating scheme that can be asses the quality of Computer-Supported collaboration processes:
1. Sustaining mutual understanding. Speakers make their contributions understandable for their collaboration partner, e.g., by avoiding or explaining technical terms from their domain of expertise or by paraphrasing longer passages of text from their materials, rather than reading them aloud to their partner.
2. Dialogue management. A smooth “flow” of communication is maintained in which little time is lost due to overlaps in speech or confusion about whose turn it is to talk. Turn-taking is often facilitated by means of questions (“What do you think?”) or explicit handovers (“You go!”). Speakers avoid redundant phrases and fillers (“um… um,” “or….or”) at the end of a turn, thus signalling they are done and the partner may now speak.
3. Information pooling. Partners try to gather as many solution-relevant pieces of information as possible. New information is introduced in an elaborated way, for example by relating it to facts that have already been established, or by pointing out its relevance for the solution. The aspects that are important from the perspective of their own domain are taken into account and they take on the task of clarifying any information needs that relate to their domain of expertise.
4. Reaching consensus. Decisions for alternatives on the way to a final solution (i.e., parts of the diagnosis) stand at the end of a critical discussion in which partners have collected and evaluated arguments for and against the available options. If partners initially prefer different options, they exchange arguments until a consensus is reached that can be grounded in facts.
5. Task division. The task is divided into subtasks. Partners proceed with their task systematically, taking on one step toward the solution after the other with a clear goal or question guiding each work phase. Individual as well as joint phases of work are established, either in a plan that is set up at the beginning, or in short-term arrangements that partners agree upon as they go. Partners define and take on individual subtasks that match their expertise and their resources. The work is divided equally so none of the collaborators has to waste time waiting for his or her partner to finish a subtask.
6. Time management. Partners monitor the remaining time throughout their cooperation and make sure to finish the current subtask or topic with enough time to complete the remaining subtasks. They check, for example, whether the current topic of discussion is important enough to spend more time on, and remind one another of the time remaining for the current subtask or the overall collaboration.
7. Technical coordination. Partners master the basic technical skills that allow them to use the technical tools to their advantage (for example, they know how to switch between applications, or how to “copy and paste”). Collaborators further arrange who may write into the shared editor at which time. At least one partner makes use of his or her individual text editor, thus allowing for phases of parallel writing.
8. Reciprocal interaction. Partners treat each other with respect and encourage one another to contribute their opinions and perspectives. Critical remarks are constructive and factual, never personal; i.e., they are formulated as contributions toward the problem solution. Partners interact as equals, and decisions are made cooperatively.
9. Individual task orientation. Each participant actively engages in finding a good solution to the problem, thus bringing his or her knowledge and skills to bear. He or she focuses attention on the task and on task relevant information, avoids distractions, and strives to mobilize his or her own as well as the partner ’s skills and resources.
 Tags: Computer Supported Collaborative Work, research, research methodology
Tags: Computer Supported Collaborative Work, research, research methodology