C. Marlow, M. Naaman, D. Boyd, and M. Davis. Ht06, tagging paper, taxonomy, flickr, academic article, to read. In HYPERTEXT ’06: Proceedings of the seventeenth conference on Hypertext and hypermedia, pages 31–40, New York, NY, USA, 2006. ACM. [PDF]
———
This seminal paper presents a taxonomy of tagging systems based on incentives and contribution models to inform potential evaluative frameworks. First, the authors explain why tagging systems are used and the different strands of research around this area, namely the social bookmarking, the social tagging systems, and folksonomies. They explain how these systems are affected by the vocabulary problem, where different users use different terms to describe the same thing.
The authors model a prototypical tagging system as having three components, a number of resourcer, tags associated to these resources and users who generated the tags. Some systems can have links among the resources and/or links among the users.
The taxonomy they define contains seven categories: tagging rights, or the system’s restriction on group tagging; tagging support, or the mechanism of tag entry being either blind (the user cannot view the tags assigned by others to the same resource), viewable or suggestive; the form of aggregation of tags around a given resource, namely collecting repeated tags generated by different users, or bag-model, or aggregating the most frequent tags, or set-model; another difference is the type of object being tagged; related to this last point is the source of the material, the resources can be supplied by the participants, by the system, or being pubicly available; additionally, the resources can be linked, grouped or separated; finally, the users can be linked, grouped or kept separated.
Concerning the user incentives, tagging is performed for different reasons: for future retrieval; for contribution and sharing; to attract attention; to play or compete; for self presentation; and finally for expressing opinions.
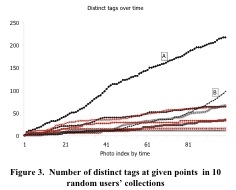
Finally the paper presents an interesting analysis of a Flickr dataset. The authors studied the growth of distinct tags for 10 randomly selected users over the course of uploaded photo. They found a number of different behaviors. In some cases new tags are added consistently as photo are uploaded. Sometimes, only few tags are used at the beginning and more later on. For many users distinct tag growth declines over time. Finaly, they found vocabulary inside a community of users to be more overlapping than the vocabulary of a random sample of unconnected users.